
こんにちは。本日はRを使ったロジスティック回帰分析の方法を紹介します。
今回紹介するロジスティック回帰分析は「あり・なし」の二値で表されることがらについて「何が最も関連するか」を判定するために使用します。
なんか、難しそう、と思うかもですがRのコード自体は難しくないですよ。
✅疑問
・Rでの回帰分析の方法を知りたい
・データの全体をまとめて特徴付けする解析方法を知りたい
このような疑問に答えていきます。
ロジスティック回帰分析とは 【複数の項目から何が影響するのか】
例えばこんなときに使います。
✓ 商品を買った人と買わない人の特徴
✓ 合格した人と不合格の人の特徴
✓ 病気の発生に関わる要因
そしてこのような結果が出ます。
✓ オッズ比:1より大きいとあるものごとが生じやすい
✓ オッズ比の95%信頼区間:対象者を増やした時のオッズ比の取りうる範囲の推定値。1を挟まなければ統計的に有意な関係性。
注意点
ただ、いくつか注意点があります。
①特徴を出せるのは目的変数が「yes・no」「あり・なし」の項目についてだけです。
②目的変数の少ない方の人数の1/10=投入する説明変数の数
①、②についての参考論文:こちら
↑
目的変数は例えば「テストの合格・不合格」のように調べたい項目のことです。少ない方とはそのうちで少ない方です。
説明変数は目的変数に影響する項目です。例えば身長、テスト点数、背中の角度などです。
実際にロジスティック回帰分析を行う【商品購入者の特徴を出す】
では実際にロジスティック回帰分析を行います。
以下のデモデータを使用します。
https://data-science-beginning.com/wp-content/uploads/2021/01/demodata-1.csv

↑50名分のデータです。横軸は9個の項目が入っています。
(年齢、男女、テスト、背中角度、足の長さ、背中曲がり有無、A、B、商品購入)項目は適当に作りました。
step1 目的変数を決めましょう
まず目的変数を決めましょう。
注意点①
✓ ①特徴を出せるのは目的変数が「yes・no」「あり・なし」の項目についてだけ。
というものがありました。
ここでは「あり・なし」のような2値のものだけ選ぶことができます。
今回は10列目の「商品購入」を目的変数にします。
0が「なし」、1が「あり」です。
step2 説明変数を決める
次に説明変数です。説明変数は目的変数に影響する項目を挙げるのでした。
ここで注意点②
「✓ ②目的変数の少ない方の人数の1/10=投入する説明変数の数」
があります。
今回のデモデータで見てみると、
商品購入=1(あり)の人は29名でした。
約30人とすると、目的変数の少ない方は商品購入=0(なし)の20名になりますね。
ということは投入可能な説明変数は「20÷10=2」となりますね。
2つしか説明変数を投入できないことになります。
少ないですね。
説明変数の数をもう少し増やしていくためにも、
ロジスティック回帰分析を行うときはサンプル数を100以上は集めた方が良いと思います。
step3 実際にロジスティック回帰分析を行う
では実際にロジスティック回帰分析を行ってみます。
データはこちら demodata.csv を使って説明します。
まずデータの読み込みですね。
・「ディレクトリ変更」で読み込みたいデータのあるフォルダを指定します。

↑
header=Tで1行目を項目のラベルとして認識させられます。
データの読み込みについて知りたい方は詳しくはこちらの記事を参考にして下さい。
Rにexcelで作ったファイルを読み込む方法【CSV形式で読み込みましょう】
ではロジスティック回帰分析を行っていきます。
解析データの抽出
今回は
目的変数が「商品購入」
説明変数は2つですので、「男女」「テスト点数」にしてみます。

↑
全体のデモデータから必要な部分だけ取ってくる形です。
<関数の解説>
・[行 , 列]:データの行と列の指定です。数値がない場合は「全て選択」の意味です。
・c (): ベクトルを生成する関数です。
ロジスティック回帰分析の実施
解析データの抽出が終わったら実際にロジスティック回帰分析を行います。

↑
<関数の解説>
・glm:一般線形モデルという推定式を使います。
・glm(解析用データ $ 目的変数の列名=., data=解析用データ, family=binomial ):
ロジスティック回帰分析の公式になります。
・family=binomial:二項分布といって、Yes/Noのような二値の値を予測する分布です。
参考:ロジスティック回帰の詳しい説明はこちら
二項分布についてはこちら
次にglmの式で出した値を表示します。
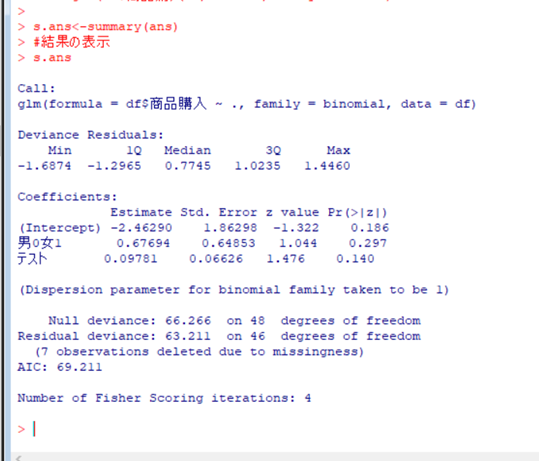
↑<関数の解説>
summary():()内の結果を表示する
すると青字の結果が出てきます。
中段にある「Coefficients」を使用します。
左から「Estimate」、「Std.Error」、「z value」、「Pr」となっていますよね。
結果を加工してオッズ比を求める
先ほどの結果の一覧から「Coefficients」を抜き出します。
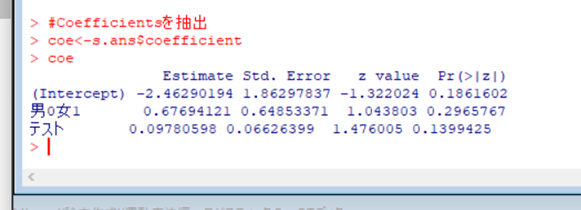
↑
<関数の解説>
coe<-s.ans $ coefficient:$はあるファイルの一部を指定して抽出できる関数です。この場合Coefficientを抽出しています。
ここでポイントですが、
オッズ比を出すためには上記のcoefficientの項目に指数関数(exp)をかけ算します。

↑
<関数の解説>
・exp() : ()をに指数関数を掛け合わせる
・ロジスティック回帰glmでは対数変換された値が出力されますのでここで指数変換しているんだと思います。多分です。。
RRがオッズ比です。
RRlowとRRhighが95%信頼区間を指します。
これでオッズ比とオッズ比の信頼区間が求まりました。最後にこの結果を一覧にまとめます。
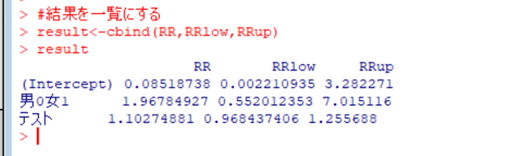
↑
<関数の解説>
・cbind():列ベクトルの結合に使う。(行ベクトルはrbind)
出来ました。
なお、ここで使ったコードですが、Rの「スクリプトを保存」で保存しておくと後ですぐに呼び出せるのでおススメです!
本日はここまでとなります。
これからも有益な記事を書いていきます。
よろしくお願いします。

